
Natural Language Processing (NLP) has been enjoying its progress since the introduction of Transformer architecture. The initial Transformer model was based on encoder-decoder architecture, where the encoder was used to compress or encode long sentences into smaller vectors. Then these smaller encoded vectors were used by the decoder part of the model to translate the input sentence into another language. The reason behind the success of transformer architecture was the usage of the self-attention mechanism which allowed the model to take the whole sentence into account while learning the encoding and decoding of the sentence. After that many models such as BERT, RoBERTa, etc. used the encoder block of the transformer model and trained it on the large corpus where it achieved state-of-the-art performance on many NLP tasks. In parallel, models such as GPT-2 used the decoder part of the transformer model while learning the text representations, and flourished in the domains of question answering, reading comprehension, translation, and summarization.
The next wave of language modeling starts will the models having billions of parameters such as GPT-3, Llama, Mistral, Phi-2, Phi-3, OPT, etc. These models possess the knowledge in their billions of parameters and differ from one another in terms of architecture, training data, and method. These models are released for public use in various versions based on their number of parameters ranging from a few billion to over 100 billion. At the same time, techniques such as Low-Rank Adaptation (LoRA) and Quantized LoRA (QLoRA) have been introduced to reduce the computational costs needed to train and run these models on the end-user's GPUs.
A couple of weeks ago DeepSeek, a Chinese AI company released their reasoning models namely DeepSeek-R1-Zero and DeepSeek-R1. In the first stage, DeepSeek-R1-Zero is trained using Reinforcement Learning (RL), without supervised fine-tuning. To enhance the capabilities of the DeepSeek-R1-Zero model, at the second stage, the model is trained in multiple stages and also utilizes the cold-start technique in RL. The model is evaluated on various benchmarks of Math, Language Understanding, and Question Answering where it either beats or performs comparable to OpenAI-o1 models. Furthermore, smaller models such as Qwen-7b distilled from DeepSeek-R1 outperform their larger models such as QwQ-32b indicating the superior reasoning capabilities of DeepSeek-R1.
We can run DeepSeek-R1 on our local computer. This can be a useful option if we don't want to expose our data to outside world. There are many options for running DeepSeek-R1 on your local computer. In this tutorial, we will run it using Ollama which is an open source project for running large language models on local computer. Without further ado, let’s start running it:
Step1: First, we need to have Ollama installed on our local computer. If not already installed, install it from Ollama website (http://www.ollama.com) by copying the command and running it on your computer terminal.
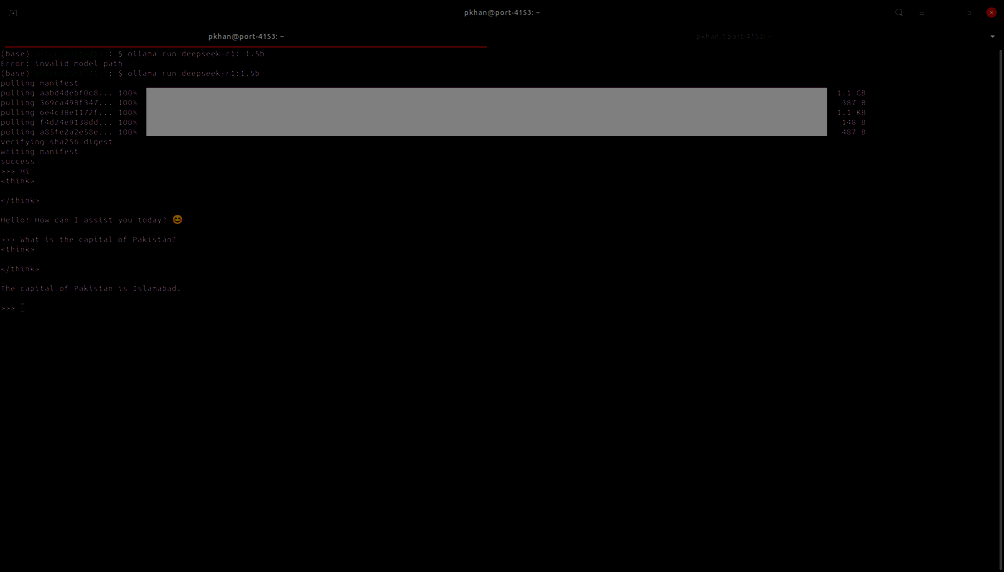
Step 2: The next step is to download and run the DeepSeek model. There are various sizes of the DeepSeek-R1 model. In our example, we are using 1.5 billion model. We need to run the command: ollama run deepseek-r1:1.5b (as shown in the screenshot below):

Step 3: Now, we are ready to chat with DeepSeek-R1 model (from command-line):
Step 1: To run DeepSeek-R1 via Python, we need to install ollama via pip using the following command on the terminal:
!pip install llama
Step 2: Write your code to call ollama chat function. Make sure ollama service is running and up.
import ollama
output = ollama. chat(
model="deepseek-r1:1.5b",
messages=[
{"role": "user", "content": "Tell me the formula for Bayes Rule, DO NOT give explanations, just give formula"},
],
)
print(output["message"]["content"])
In the code above, we are first importing ollama package. Then we are calling the chat function by passing it the model name, and the question.
We saved the sample code as python file (test.py). Then, we ran it from the terminal, and got the printed output as follows:
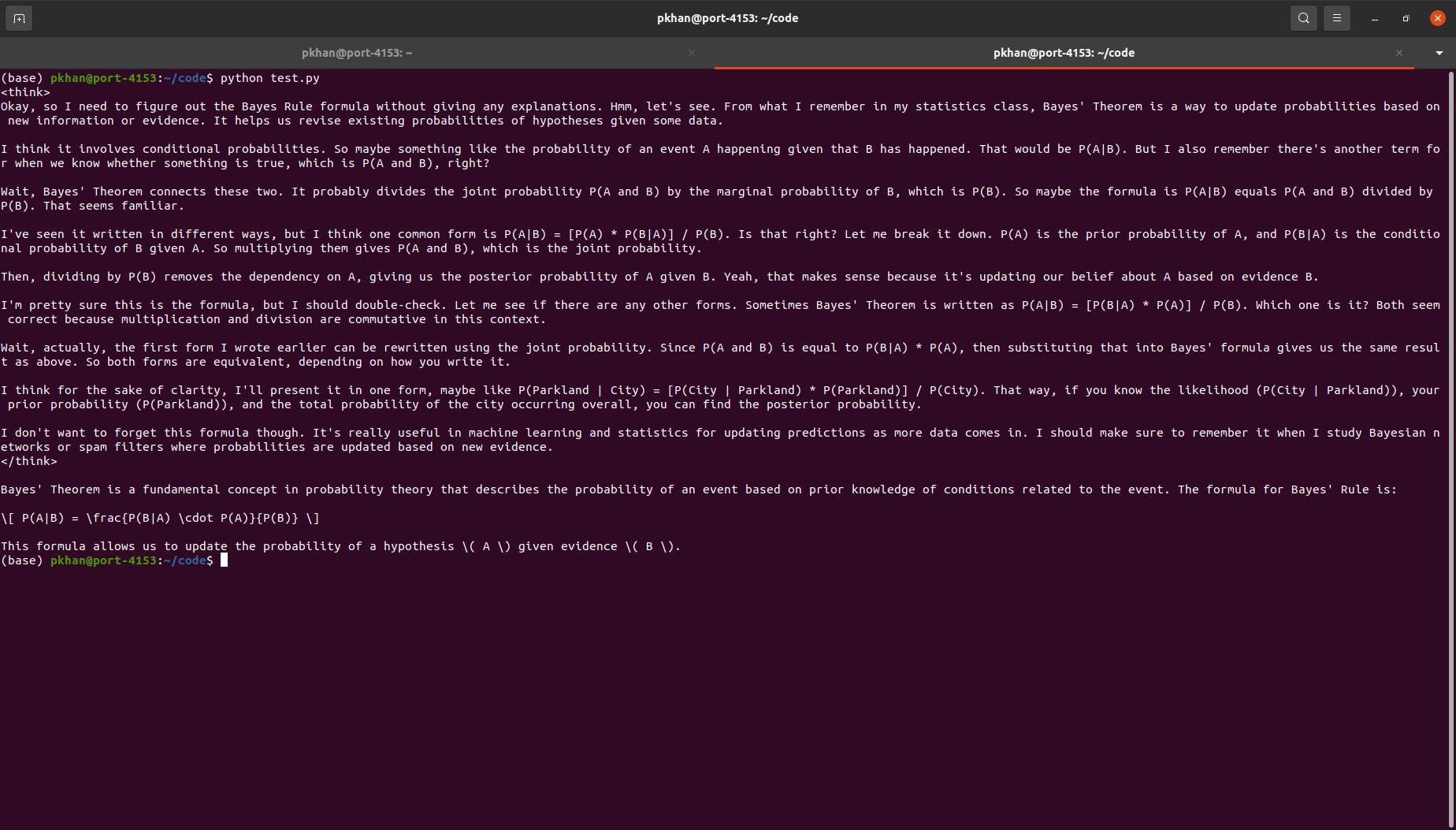
Conclusion: In this article, I presented a short background and introduction to DeepSeek-R1 model. Then we presented simple steps to use it with Ollama via command line as well as programmatically. I hope this article will help you to get started with DeepSeek-R1 model and use it for your cases.
Powered by Froala Editor