As language models become increasingly sophisticated, developers and businesses are exploring different ways to utilize their full potential. Among the most talked-about techniques are prompt engineering, retrieval-augmented generation (RAG), and fine tuning. Although these approaches may seem similar at first glance, each has its distinct applications and benefits. In this blog, I will break down what these methods are, how they differ, and when you might choose one over the others.
What is Prompt Engineering?
Prompt engineering is the art of crafting input queries—also known as “prompts”—to get the best possible results from a language model. Instead of altering the model’s inner workings, prompt engineering focuses on how you ask the question. Think of it as learning to speak the model’s language.
Key Points:
- Input Design: The focus is on designing clear, concise, and contextually rich prompts.
- No Model Modification: It doesn’t require any changes to the underlying model.
- Versatility: With the right prompt, even a general-purpose model can be guided to produce specialized outputs.
- Rapid Iteration: It’s often the quickest way to experiment with different outputs, making it ideal for prototyping or one-off tasks.
When to Use Prompt Engineering
- Prototyping Ideas: If you’re testing how well a model can perform a task, a well-designed prompt can yield surprisingly accurate results.
- Cost Efficiency: Since there is no extra training involved, prompt engineering can be a computationally low-cost way to achieve good outcomes.
- Dynamic Tasks: For tasks where context changes frequently (such as conversational AI), crafting dynamic prompts can be more effective than static training.
What is Retrieval-Augmented Generation (RAG)?
RAG stands for retrieval-augmented generation. This method augments the generation capabilities of language models by integrating an external retrieval mechanism. In simple terms, RAG allows the model to fetch relevant documents or data snippets from a large corpus and then use this additional context to generate more accurate and informed responses.

Key Points:
- External Knowledge: RAG systems typically combine a traditional language model with a retrieval system (like a search engine) that finds documents or passages relevant to the prompt.
- Improved Accuracy: By grounding answers in actual data, RAG can provide more accurate, up-to-date, and contextually relevant responses, especially for relatively changing topics.
- Hybrid Approach: This method bridges the gap between a closed-book language model and an external knowledge base, effectively keeping the model “informed” about recent developments or specialized knowledge.
When to Use RAG
- Fact-Checking and Up-to-Date Information: When accuracy and current information are critical—such as in news summarization or academic research—RAG can be a powerful tool.
- Domain-Specific Tasks: For specialized fields (like legal, medical, or business contexts) where up-to-date information is essential, integrating an external retrieval system helps overcome the static knowledge cutoff of the base model.
- Dynamic Query Handling: RAG systems are particularly useful when the underlying data changes frequently, ensuring that the generated text remains relevant over time.
What is Fine Tuning?
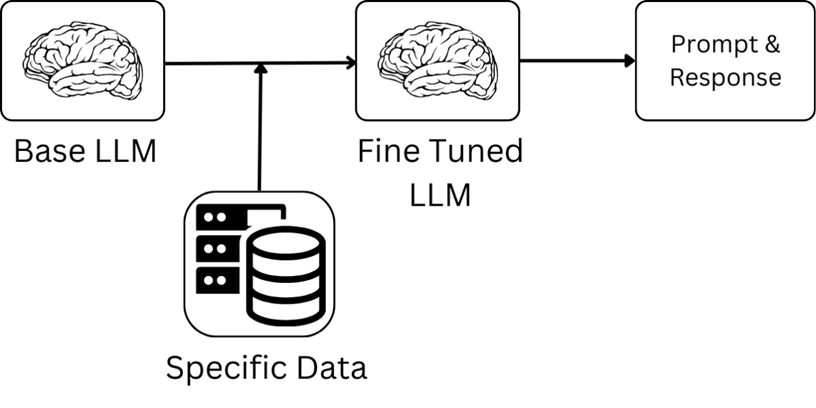
Fine-tuning involves taking a pre-trained language model and further training it on a specific dataset so that it becomes tailored to a particular task or domain. Unlike prompt engineering, which works at the input level, fine-tuning adjusts the model’s parameters directly.
Key Points:
- Model Customization: Fine tuning allows for the modification of the model’s weights, enabling it to perform better on a specialized task.
- Data Dependency: The quality of the fine-tuned model largely depends on the dataset used. High-quality, relevant data can dramatically improve performance.
- Resource Intensive: This approach typically requires more computational resources and time compared to prompt engineering and RAG.
- Stable Results: Once fine-tuned, the model’s behavior becomes more predictable for the targeted tasks, making it a good option for applications that need consistent performance.
When to Use Fine Tuning
- Specialized Applications: When you have a very specific task or domain (e.g., legal document analysis, customer service chatbots), fine-tuning can produce a model that understands even the slightest changes of your field.
- Long-Term Deployments: For products or services that require stability and consistency over time, investing in fine-tuning can lead to a more robust solution.
- Performance Improvements: If prompt engineering and RAG aren’t providing the level of accuracy you need, fine-tuning the model on domain-specific data might be the answer.
Conclusion
In today’s rapidly evolving AI landscape, understanding the tools at your disposal is key to leveraging their power effectively. Whether you’re using prompt engineering to quickly prototype ideas, RAG to ground your responses in reliable data, or fine-tuning to craft a specialized solution, each technique offers unique advantages that can be tailored to your project’s needs.
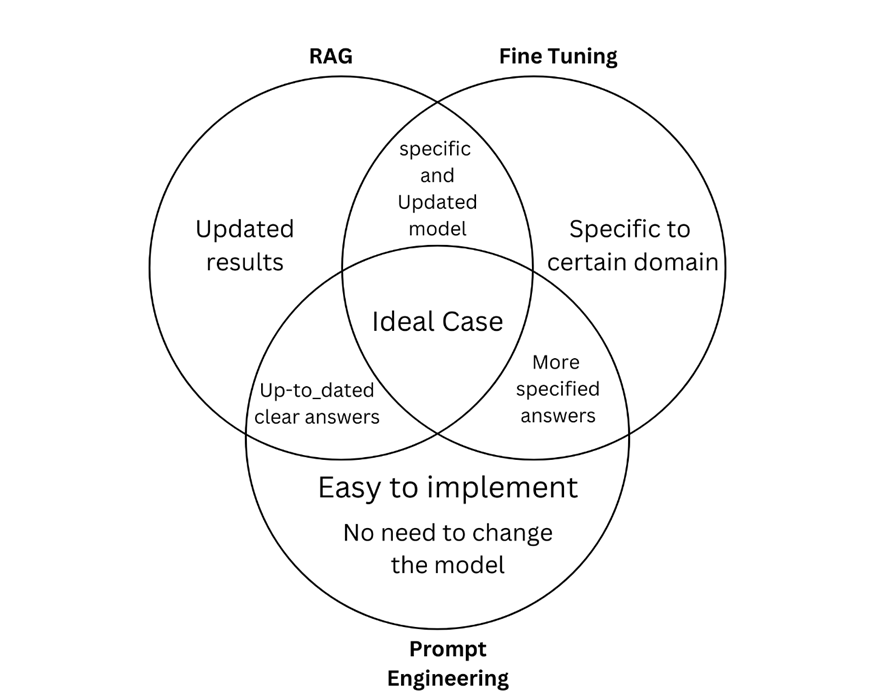
By assessing the strengths and trade-offs of each method, you can make informed decisions that not only meet your current requirements but also scale with your future ambitions in the dynamic world of natural language processing.
Powered by Froala Editor
