
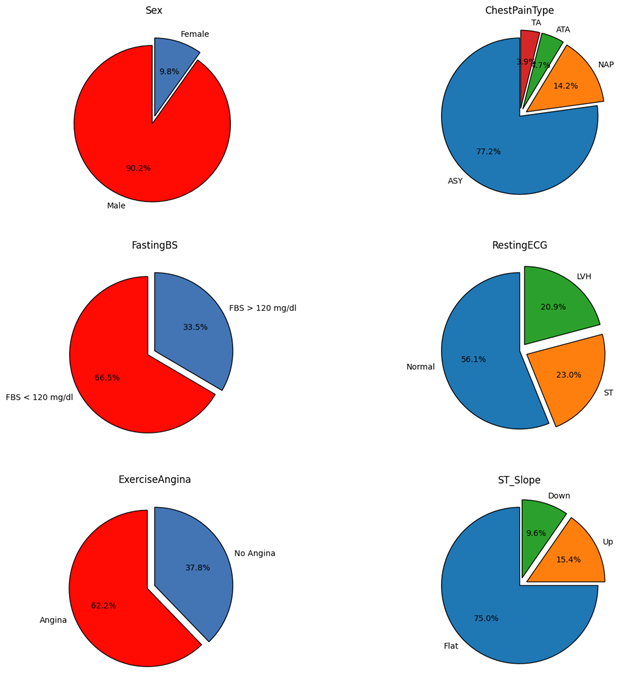
Cardiovascular failure is a medical condition that happens whenever the heart cannot pump enough blood throughout the body. This shows that the body isn't getting sufficient oxygen and nutrients to function correctly. Heart disease happens whenever there is a reduction in the heart muscle's capacity for pumping blood due to weakness or injury. As a result, blood may accumulate in the body and cause ballooning in your legs and belly in addition to breathing difficulties in the lung area. Heart trouble is a common ailment that millions of individuals experience globally. Although it can happen around any stage of life, elderly folks experience it frequently.
Around the world, cardiovascular disease is a prevalent and dangerous ailment that affects many people. The heart's capacity to circulate pump blood throughout the body suffers whenever the heart's muscles decrease and sustains an injury. Numerous symptoms, such as exhaustion, swollen leg, difficulty of breathing, and an erratic or fast heart rate, may arise from illness.
Heart failure treatment presents many difficulties for patients as well as doctors. To maximize patients' success rates and standard of life, an extensive plan involving rapid detection, precise evaluation, customized therapies, and continuous tracking and oversight is needed. Conventional methods of treating heart failure depend on clinical evaluations, diagnostic procedures, and established treatment guidelines. These methods might not, however, always be adequate to address each patient's unique complex needs or to foresee and stop the advancement and consequences of their diseases.
The integration of artificial intelligence (AI) in the medical field presents fresh chances to tackle these issues and enhance the treatment of heart failure. Large volumes of patient statistics, such as health records, ultrasounds, biological information, as well as gadgets sensor data, might be analyzed by artificial intelligence (AI) tools, such as machine learning algorithms and predictive analytics, to find patterns, trends, and knowledge that could not be obvious to individual doctors. AI has a lot to offer heart failure patients in terms of possible improvements in clinical results, increased patient satisfaction, and more effective utilization of medical facilities.
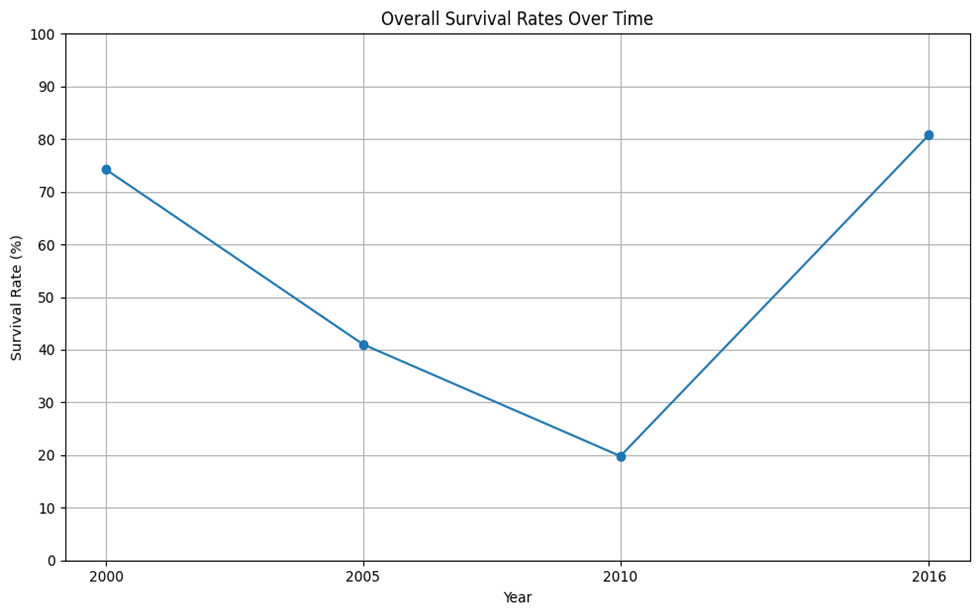
The graph of lines illustrates how overall survival rates for people with heart disease increased significantly between 2000 and 2016, reaching 80.8% by that time. At varying periods, notable advancements were noted: 74.5% in 2000, 41.0% in 2005, 20.0% in 2010, and 48.2% in 2016. Source of information.

Depending on the area of the heart that is impacted and how well it can pump blood, there are many forms of heart failure. Two of the primary categories are:

AI holds great promise in improving the management of heart failure, offering several benefits:


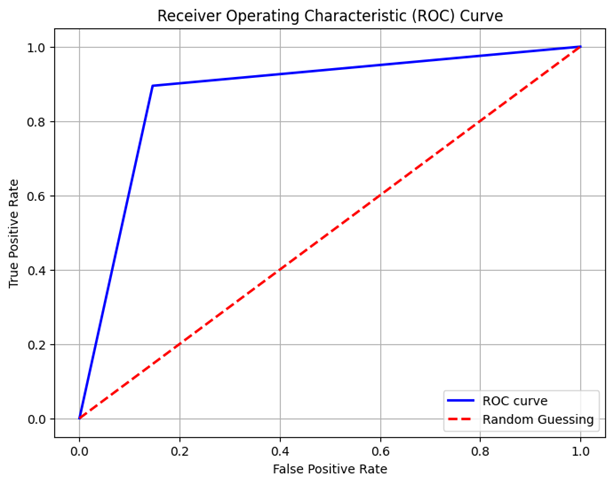
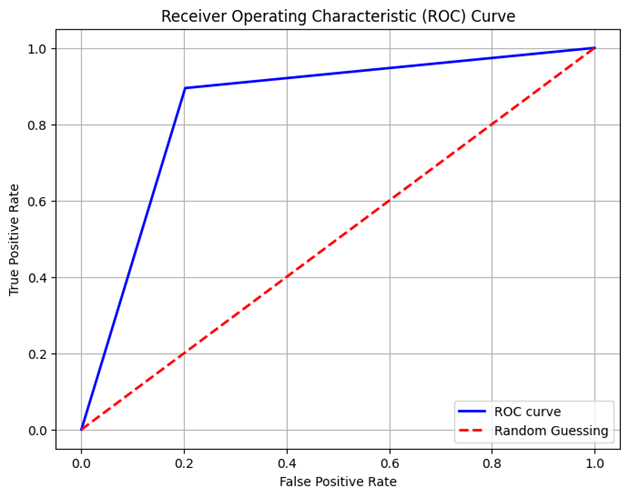
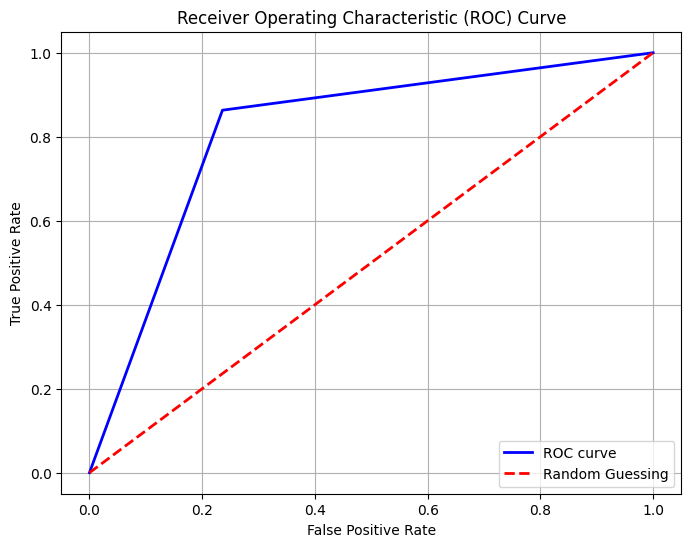
To assess the performance of the logistic regeneration model many key matrices are computed. These include accuracy, cross validation score (ROC AUC), confusion matrix and classification report Accuracy represents a proportion of classified examples out of all the examples in the test set. The cross validation score gives an approximate of the models anticipating performance around different train test splits additionally, the doubtful matrix visually gives out the performance of the classifier revealing the number of true positive, false positive, true negative and false negative guess. Moreover the code creates a Receiving operating characteristics (ROC) bend to visualize the exchange in middle of true positive rate (sensitivity) and false positive rate (1 specificity) over different threshold values This curve is a handy tool for evaluating the performance of binary classifier chiefly when taking into consideration in the middle of sensitivity and specificity.
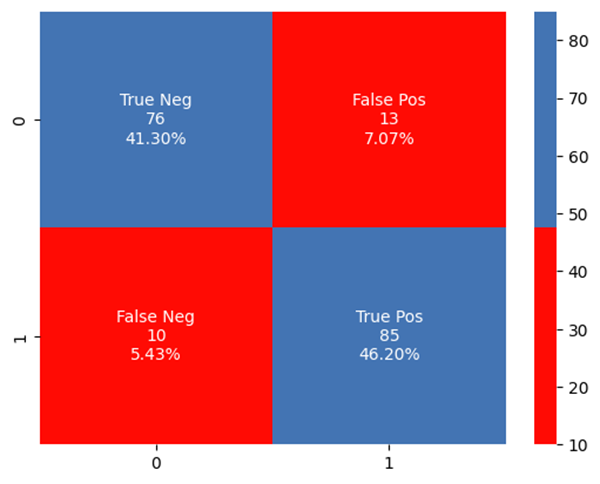
Confusion Matrix
A binary classification operation is carried out by the Support Vector Classification (SVC) algorithm. The supervised learning technique called SVC looks for the hyperplane in a space with multiple dimensions that best divides each class. Since SVC is configured with a linear kernel in this particular instantiation, the algorithm is predicated on the assumption that the data are linearly separable in the input space. Furthermore, 0.1 is specified for the regularization variable (C). The compromise between minimizing the classification error and maximizing the margin is managed by this parameter. A softer margin, which permits certain misunderstandings in favor of a wider border, is indicated by a smaller C score.
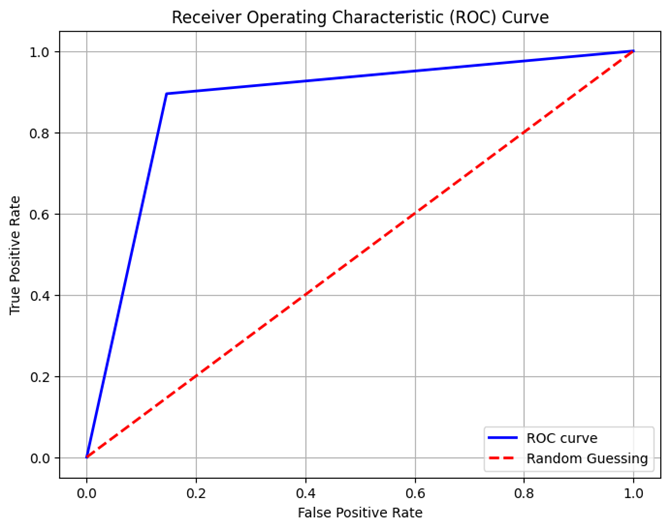
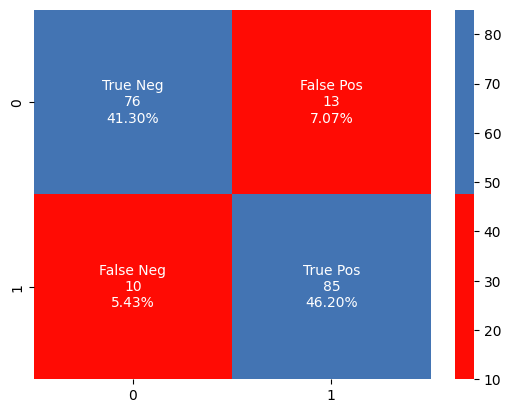
Confusion Matrix
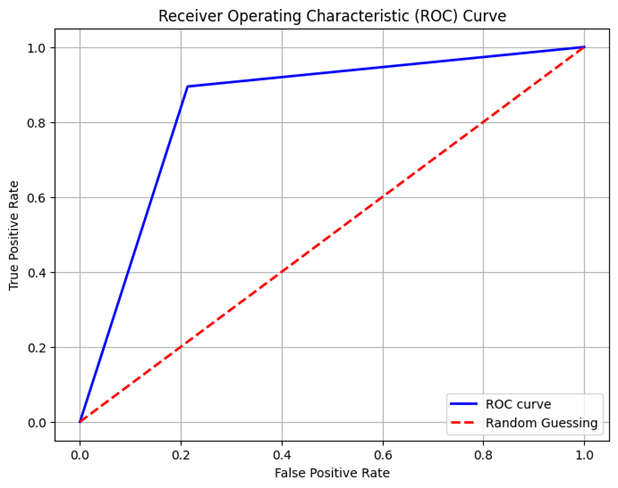
A Decision Tree Classifier is a popular machine learning method for classification applications. Random_state is used to configure the random seed in a consistent manner. Through the establishment of a certain random state, we verify that the output of the model remains consistent throughout multiple runs. The parameter max_depth indicates the deepest level of the decision tree. That controls the maximum number of levels in the hierarchy. A smaller number prevents overfitting by lowering the tree's degree of difficulty. The number min_samples_leaf indicates the absolute minimum number of samples required at a leaf node.Through verifying the leaf nodes contain an adequate number of information points, it assists in controlling the tree's size and avoids excessive fitting. classifier_dt is a DecisionTreeClassifier object having min_samples_leaf set to 1 and max_depth set at 4. These factors were selected to strike a compromise between model complexity and performance, either by experimentation, domain expertise, or hyperparameter optimization. The Receiver Operating Characteristic (ROC) curve is plotted by the model () function after the DecisionTreeClassifier has been fitted to the training data (x_train and y_train) and its performance assessed on the test data (x_test and y_test). More information about the accuracy of the classifier is provided by the model_evaluation() function, which shows the confusion matrix and classification report.
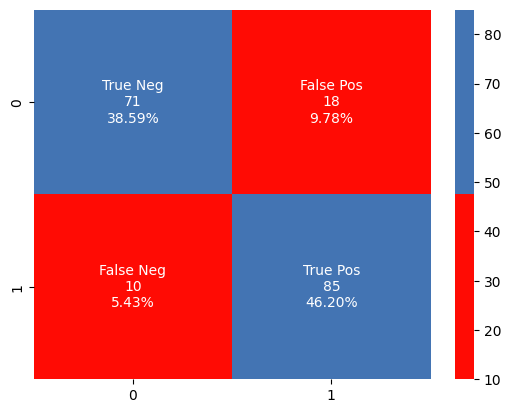
Confusion Matrix
A decision tree-based ensemble learning technique is called Random Forest Classifier. Throughout training, it builds several decision trees, from which it produces the mean prediction (regression) of each individual tree or the modal (most frequent class) of the classes (classification). The maximum depth of every tree in the forest is specified by this option. Simply limiting the depth of the trees to a figure like 4, you can lessen the likelihood of overfitting by making the separate trees less complicated.Reproducibility is the results that is ensured by random state. Whenever the program is executed, its random number generator begins functioning with the same seed value when it is set to a given value, such as 0. This produces the same series of random numbers and, consequently, trains the same model. The model method fits the RandomForestClassifier to the training data (x_train, y_train), determines and displays several metrics for assessment including accuracy, cross-validation score (using RepeatedStratifiedKFold), and ROC_AUC score, and generates forecasts on the experimental data (x_test). It also shows the difference among the true positive rate and false positive rate by plotting the Receiver Operating Characteristic (ROC) curve. Through creating a confusion matrix, publishing a classification report, and displaying the confusion matrix, the model_evaluation method assesses the results of the classifiers.
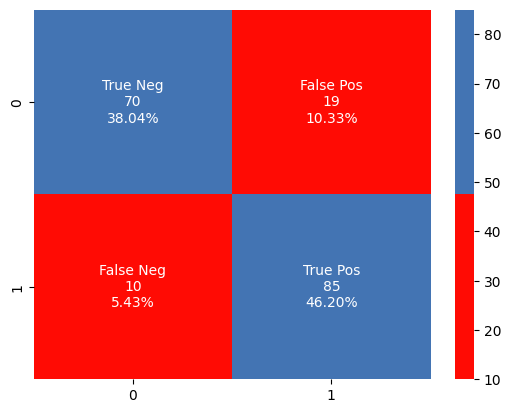
Confusion Matrix
A machine learning model called K-Nearest Neighbors Classifier has been used for classification task. It depends on a principle of resemblance across data points and is a member of the supervised learning algorithm group. The most frequently observed category label from the k closest data points from the training set is assigned to the predicted label for the latest data point when employing the K-nearest neighbors technique to predict the class label for a new data point. The size of the leaf nodes in the KD tree or Ball tree data structures—that are utilized to perform efficient nearest neighbor searches—is controlled by the leaf_size option. While shorter leaves could result in speedier searches, they may require extra RAM. The value of leaf_size is 1 in the code. The number of neighbors to take into account when generating prediction is specified by the option n_neighbors. That establishes the number of nearest neighbors that will ultimately be utilized for casting ballots in an additional point's class label. When n_neighbors is set to 3, the framework takes into account the class labels of the three neighbors which are closest near it. The strength factor for the distance Minkowski calculation is represented by such p parameter.
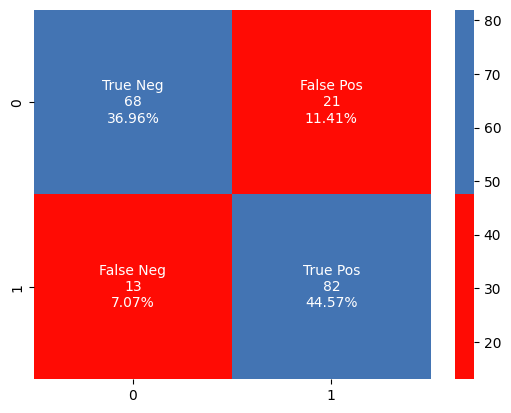
Confusion Matrix
Machine Learning Algorithm | Accuracy | Cross-Validation Score | ROC Score |
Logistic Regression | 87.50% | 91.12% | 87.43% |
Support Vector Classifier | 87.50% | 90.53% | 87.43% |
Decision Tree Classifier | 84.78% | 89.09% | 84.62% |
Random Forest Classifier | 84.24% | 92.91% | 84.06% |
KNN Classifier | 81.52% | 89.34% | 81.36% |
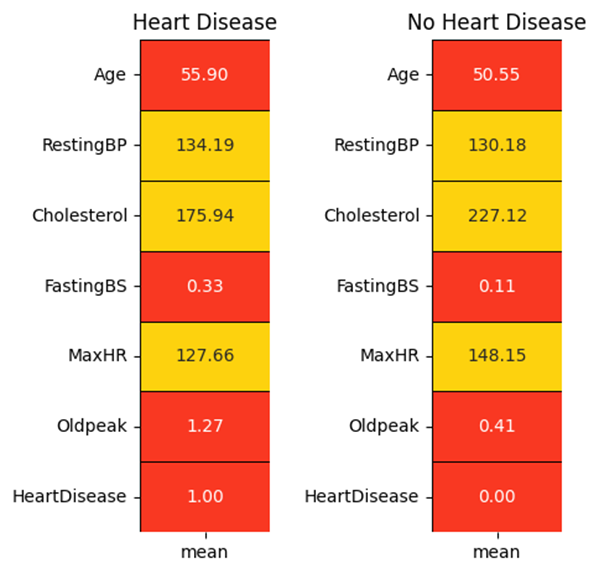
Implementing machine learning algorithms like logistic regression, decision trees, support vector classifiers, and K-Nearest Neighbors classifier, the study's ultimate goal was to establish models of prediction of cardiovascular disease risk identification. Positive outcomes are indicated by the accurate values for every model, which range from 81.52% to 87.50%. Similar to the Random Forest and Decision Tree classifiers, the SVC and Logistic Regression models represented the most accurate classification techniques. It turned out that the K-Nearest Neighbors classifier was more suitable .Examining heart failure risk factors revealed many noteworthy traits that are linked to an elevated risk of heart disease. These included having a family history of coronary artery disease (CAD), insulin resistance, heart valve problems, smoking, drinking alcohol, and being overweight with heart illness. Understanding these risk factors is essential for managers, detection, and treatment.
Powered by Froala Editor