Fresh Vs Rotten Fruits Classification with Streamlit
Summary:
In the scenario of how to feed the world in the future free from food scandals and wastage, such discrimination is a must. In this paper, work focuses on the use of YOLOv8n model for the differentiation and identification between fresh fruits and those that are rotten. Based on the YOLOv8n’s rich object detection features, the model was calibrated using a train dataset of different fruit types both fresh and at different stages of deterioration. Due to its relatively simple structure the proposed model allows having fast analytics, making it suitable for applications to be executed in real time, particularly in supermarkets, warehouses or automated sorting centers.
For improving the usability of the webapp, we incorporated a graphical interface utilizing the Streamlit, an open-source Python library to build webapps. Streamlit is the front end of the system where the users can upload the images and view the detection results easily since the system has been designed to be user friendly especially for the non-technical persons. From these findings, we can claim that YOLOv8n is capable of achieving a high level of accuracy when discriminating fresh and rotten fruits, surpassing the previously used image processing approach and any of the YOLO’s previous versions. This work reveals the possibility of using deep learning models accompanied with simple web-link interfaces to improve quality control and supply chain strategies to food businesses.
YOLOv8 Working and Model Training Process
1. Data Collection and Preprocessing:
- Dataset Collection: Collect as many as possible images of different varieties of fruits which are to be in fresh as well as in spoiled stage. It is required to have more than one kind of fruit so that various tests will be conducted on them: Several samples of fruit should be taken taken under different lighting and background.
- Annotation: Use annotation tools such as LabelImg to label the images. Each fruit in the image is marked with a bounding box and labeled as either "fresh" or "rotten."
- Data Augmentation: Auto rotate, auto flip, auto scale the images and adjust the hue and saturation level for the same image to add variations in training data set. This also seems to make the model more generalizable and decreases the probability that the model will over fit the data.
2. Model Architecture:
- YOLOv8n Overview: YOLOv8n is the newest object detection model known to be both efficient and accurate, it stands for You Only Look Once version 8 nano. It takes the whole image at once and describes it by predicting the boundaries running through the objects and the likelihood of the objects belonging to specific classes at once.
- Network Structure: YOLOv8n uses a convolutional neural network (CNN) to extract features from the input images. It then applies these features to detect objects and classify them into the predefined categories (fresh or rotten).
3. Training Process:
- Initialization: Import and launch the YOLOv8n model based on the weights obtained from retraining on a large dataset like COCO. This type of transfer learning gives the model a good foundation and it is even better when made to work fewer epochs during its training phase.
- Custom Configuration: Configure the YOLOv8n model for the specific task of fruit classification. Set parameters like input image size, batch size, learning rate, and the number of epochs.
- Loss Functions:
- Localization Loss: Calculates the degree to which the coordinates of the extracted bounding boxes correspond to ones that have been manually sought.
- Confidence Loss: Evaluates the model's confidence in predicting whether a bounding box contains an object.
- Classification Loss: Assesses the accuracy of the predicted class probabilities (fresh or rotten).
4. Training Execution:
- Forward Pass: For each training iteration, input images are fed into the network. The model outputs bounding box coordinates, confidence scores, and class probabilities.
- Loss Calculation and Backpropagation: Compute the total loss using the predicted outputs and backpropagate this loss through the network. Update the model weights using an optimization algorithm like Adam or SGD to minimize the loss.
- Validation: It is recommended to evaluate the model on a validation set from time to time to check performance. Metrics such as precision, recall, and mean Average Precision (mAP) can be used in measuring the accuracy of the model. Optimize hyperparameters based on validation performance for improved model performance.
5. Post-Training Evaluation:
- Testing: Once trained, test the corresponding model on a set of test data that has not been given as input to the constructor under examination. This step will help the model to minimize the chances of over-fitting and would be able to perform well on other data that we have not used in training the model.
- Fine-Tuning: If necessary, fine-tune the model by further training with adjusted hyperparameters or additional data to improve accuracy.
6. Deployment:
- Streamlit Interface: Create a user-friendly interface using Streamlit, an open-source Python library for building web applications. This interface allows users to upload images, run the detection model, and view the results.
- Integration: Integrate the trained YOLOv8n model with the Streamlit application. Optimize the system for fast inference to ensure real-time performance.
How It Works in Practice
Step-by-Step Workflow:
- Image Upload: Users upload an image of fruits through the Streamlit interface.
- Image Preprocessing: The uploaded image is preprocessed (resized, normalized) to match the input requirements of the YOLOv8n model.
- Model Inference: The preprocessed image is fed into the YOLOv8n model. The model processes the image in a single forward pass, predicting bounding boxes around each detected fruit along with confidence scores and class labels (fresh or rotten).
- Post-Processing: The predicted bounding boxes and the class labels of the detected objects are further examined to remove any detections whose confidence scores are low. Non-Maximum Suppression (NMS) may be employed to suppressing bars that share a significant overlap with other bars.
- Result Display: The final detection results, including bounding boxes and labels, are displayed on the uploaded image in the Streamlit interface. Users can see which fruits are classified as fresh or rotten.
- User Interaction: Users can interact with the interface to upload new images, view results, and possibly adjust settings for detection sensitivity.
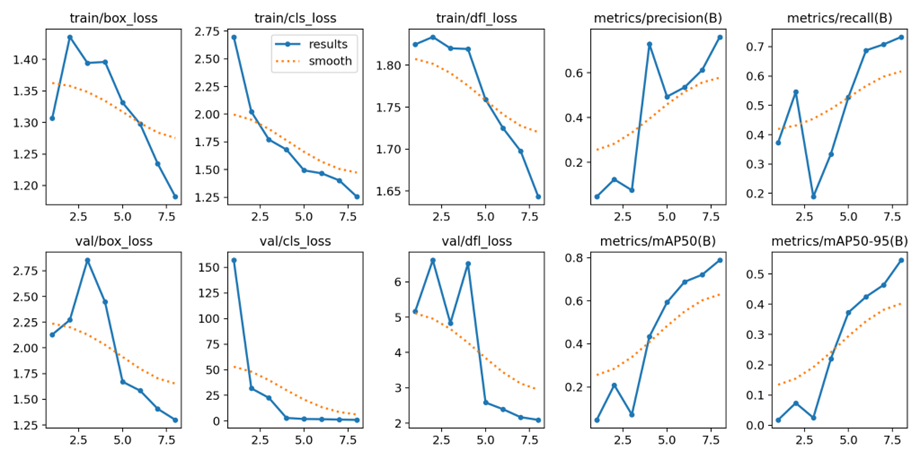
Loss Function Graphs:
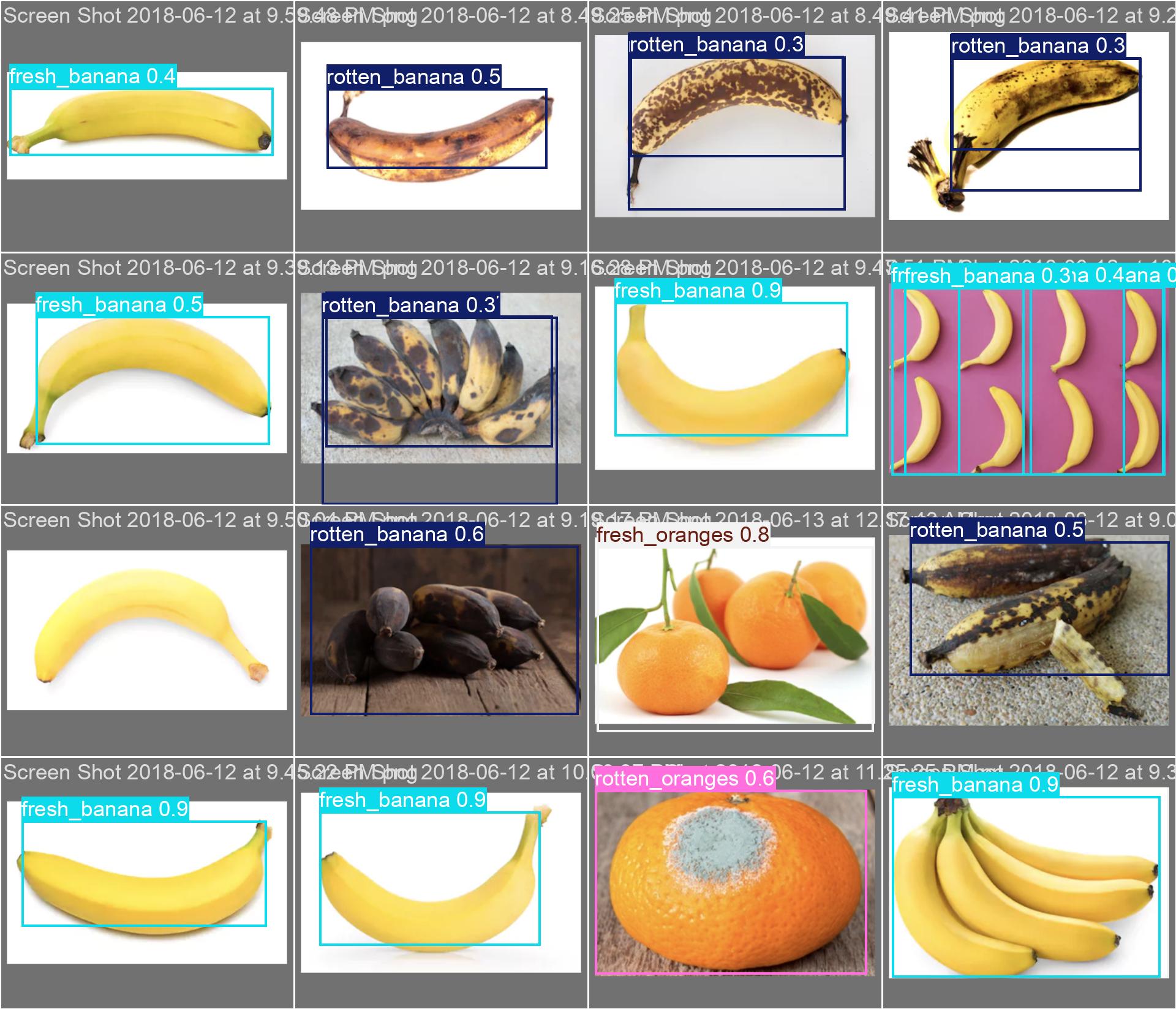
Results of Yolov8 Model:
Deployment with Streamlit Interface:
- Streamlit Setup:
- Develop a Streamlit application to create an interactive web interface for the fruit classification system.
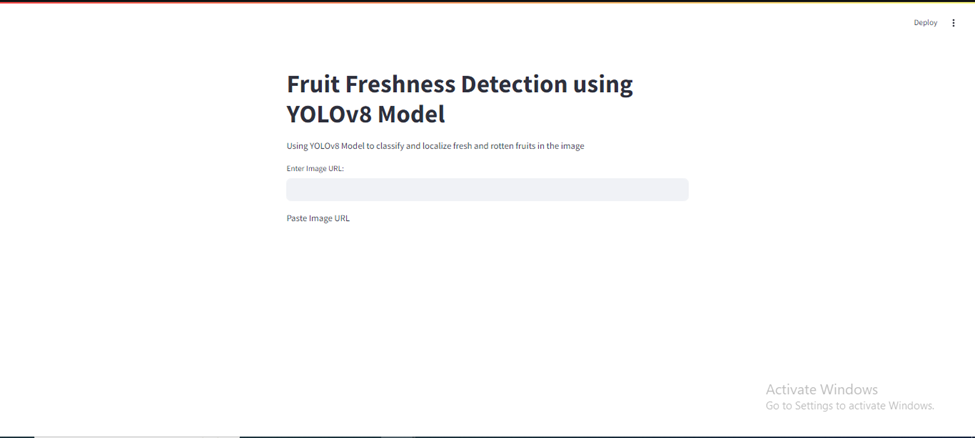
- User Input:
- The user provides the URL of the fruit image via the Streamlit interface.

- Image Display:
- The Streamlit app fetches the image from the URL and displays it to the user.
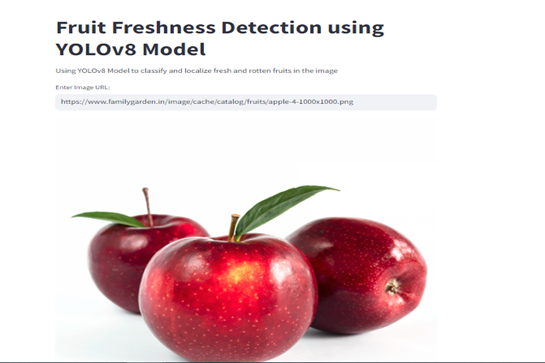
- User Interaction:
- The user clicks the "Classify" button to initiate the classification process.
- Model Inference:
- The Streamlit app preprocesses the image (resizes, normalizes) and feeds it to the YOLOv8n model.
- The model processes the image, predicting bounding boxes around detected fruits and classifying them as fresh or rotten.
- Post-Processing:
- The predicted bounding boxes and class labels are then post processed by applying a threshold on the detection score. In this case, Non-Maximum Suppression (NMS) may again be used in order to remove any overlapping bounding boxes.
- Result Display:
- The final results, including bounding boxes and labels, are displayed on the image in the Streamlit interface, showing which fruits are fresh and which are rotten.
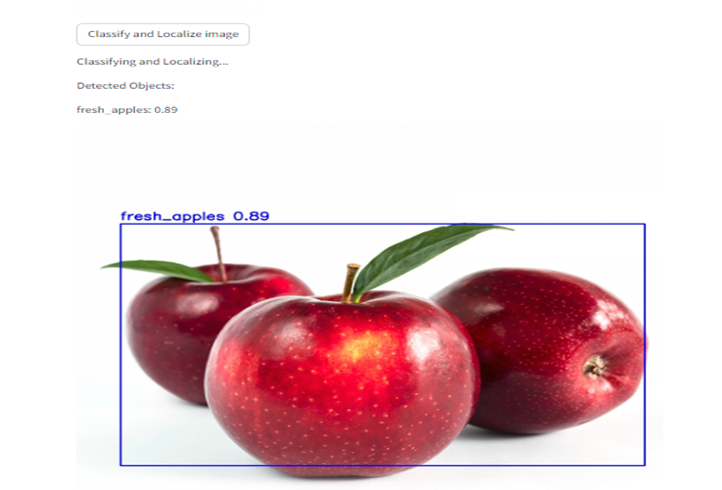
Fresh Fruit Result:
Rotten Fruit Result:

Conclusion:
The YOLOv8n model has been successfully implemented to classify fresh and rotten fruits in supermarkets, warehouses, and automated sorting systems. Its advanced object detection capabilities and lightweight architecture enable accurate real-time classification. The model uses transfer learning and data augmentation techniques to distinguish between fresh and rotten fruits. Once the the model is trained then have to develop a real time application which actually built on the Streamlit application allows users to upload images, classify fruits, and view results. The system offers potential benefits like improved quality control, reduced food waste, and optimized supply chain processes. Future work could expand the dataset to include more fruit varieties and stages of freshness.
Future Recommendations:
The YOLOv8n deep learning model designed to improve food quality control, reduce waste, and optimize supply chain efficiency in the food industry. It captures images of various fruit types and varieties, undergoes fine-tuning and hyperparameter optimization, and is designed for real-time applications. The model includes batch processing, image annotation tools, and analytics dashboards, and incorporates user feedback mechanisms for continuous improvement. It is open-source, fostering collaboration and knowledge sharing, and environmentally friendly, ensuring data privacy and security. These recommendations aim to enhance the application of deep learning models for fruit classification.
Powered by Froala Editor
