
In the era of AI, it seems very daunting to search for a specific entity in a long document. The documents, which are 2000 words, can be very tricky to investigate and grasp what’s going on in them. To make things easier we have NER systems that can easily classify words into the specific category, and we can ignore the rest of useless information in a document. In this article I am going to discuss how you can implement it in a simple way, and it can be used to see a person belonging to which organization and its occupation. But before going into it I would like to tell you about BERT. We will be using it to deploy our NER and a little in-depth detail about NER itself. The aim of this article is to give a beginner friendly approach for the BERT implementation and its use for NER.
Name Entity Relationship (NER):
Named Entity Recognition is a sub-task of information retrieval constituent of Natural Language Processing (NLP). The focus of the NER is to look for entities and classify them in the given text. The entities can be anything that you give the label to such as persons, organizations, locations, dates, and more. It extracts structured information from raw data in text which makes it easier to analyze and understand.
Different Approaches for NER:
NER performs the required dependency for a variety of NLP applications, which include retrieval of content from textual data, response to various queries available online, translation from one language to another, summaries, and much more. With its ability to identify and categorize, NER is used extensively to recognize the context behind applicable knowledge obtained from the ever-expanding text-based data. NER can be implemented using two main approaches; One is the rule-based approach which consists of the patterns and rules that can be utilized to identify the entities. It is effective and works in such environments where language is predictable. It is less likely to be scaled and adaptable for new contexts.
Machine Learning based NER is particularly based on the deep learning models. They have advanced and provided the state-of-the-art in NER. These models utilize the pretrained models and then fine tuning them for NER. The advantage of using the deep learning model is that the context of the word is also included especially if transformers are utilized.
Challenges and Evaluation Metrics:
The challenges that are faced by NER consist of the ambiguity and variability of the language. The context of the word can be different in different sentences. If I give an example, then we can say that “Apple” can be a fruit as well as a company. There is need of the contextual understanding which can then lead to proper entity assigned to word. One of the other challenges is the use of abbreviation. For Example, “United States” as “U.S” will be difficult to detect a Country Entity. In such scenarios it becomes difficult for the NER to get an idea regarding the entities in the text-based data.
Metrics including precision, recall and f1 score are used to evaluate the performance of NER. The high performing and efficient NER systems has the balance between the precision and the recall. The improvements in the model architectures, and the diverse annotation of the datasets will help in the development of more sophisticated methodologies of the evaluation of NER.
Importance of NER:
NER (Named Entity Recognition) is a significant component of NLP (Natural Language Processing), which enables the required processing of text that’s unstructured by extracting useful information and structuring it, categorizing the valuable information efficiently. The importance of such components is very much because most textual data found on almost all the internet is unprocessed and unutilized. It allows us to use its ability to tell specific entities within textual data, classifying the ones found under people, organizations, locations, time expressions, quantities and a lot more. Once the NER process the data structured data is obtained which allows us to take the appropriate actions and facilitate tasks like data analysis, information retrieval and knowledge graph construction.
In today’s world, NER is the foundation for information retrieval – the process of withdrawing organized particulars from chaotic and amorphous data available so readily on web pages, articles, social media posts, research papers, etc. It facilitates information exchange using features which includes Structured data creation, Enhanced contextual understanding, Knowledge graph construction and Improved information retrieval by entity recognition and categorization.
Undoubtedly, NER goes beyond simply identifying entities found in text i.e. it enables a deep understanding of these entities by considering their context and relationship. Its underlying abilities include Removing Ambiguity, Relationship extraction reference resolution, Event recognition and Sentiment analysis.
Above all, NER is extremely applicable in improving how much a language is understandable by machines. It creates a connection between meaning represented by words and their raw data, understanding the fundamentals of human communication enabling a variety of practical uses. It builds its foundation for meaning and represents the “who,” “what,” “when,” and “where” of our world. Consequently, NER’s importance is validated for its use in Fraud Detection, Social Media Monitoring, Question Answering Systems, Machine Translation and Powering Intelligent Applications like chatbots.
Certainly, NER is an extremely useful tool in NLP, its applications are spread across far and wide. Its ability to extract key entities from text authorize transformation across various domains like Healthcare, Finance, Legal, E-Commerce makes it a crucial component, one that we rely on heavily in our day-to-day lives. In conclusion, research continues to refine NER techniques which will improve its capabilities additionally, enabling one to extract even richer insights from the ever-expanding ocean of textual data.
BERT:
Google inaugurated a vigorous natural language processing (NLP) model called Bidirectional Encoder Representations from Transformers (BERT) which was based on the transformer architecture in a study which was put out in 2018. Depending on the context of a word used within a sentence, BERT made use of its representation and produced word embeddings that are contextualized. Not only did this help in most NLP tasks, but BERT achieved a cutting-edge performance in many benchmarks for NLP including query response, sentiment analysis, NER and much more. It gave rise to development in robust transformer-based models.
Implementation of NER using BERT:
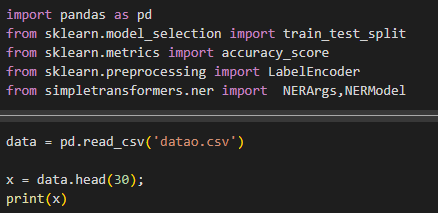
Dataset:
The Dataset is made using Chat GPT and Bard.
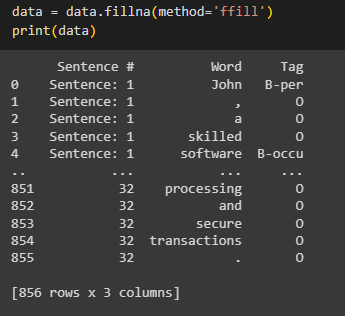
Sentence # | Word | Tag |
Sentence: 1 | John | B-per |
| , | O |
| a | O |
| skilled | O |
| software | B-occu |
| developer | I-occu |
| at | O |
| Microsoft | B-org |
| , | O |
| created | O |
| a | O |
| new | O |
| application | O |
| to | O |
| streamline | O |
| business | O |
| processes | O |
| , | O |
| showcasing | O |
| his | O |
| innovation | O |
| and | O |
| expertise | O |
| in | O |
| software | O |
| solutions | O |
| . | O |
Preprocessing:
We are going to use Google Colab for the implementation of NER.



Training of Model:

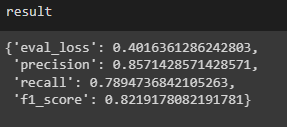
Model Evaluation:

Prediction and Output:

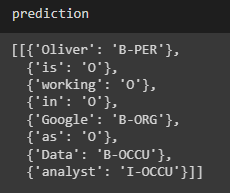
We can see that the model has classified the sentence into the relevant tags.
These articles give simple implementation of the NER using BERT. I hope you found our article helpful for implementing BERT in Named Entity Recognition (NER). NER can be implemented and helpful in getting out the relevant information. We've covered the steps to create your data set and implement NER, with links to resources for any issues you may encounter. Feel free to check them out for assistance.The link to my data set and .ipynb file can be acessed from Github.
Powered by Froala Editor