
In this article I will be discussing video captioning and its techniques using Deep Learning. Video Captioning is still an ongoing research problem and is explored by a lot of researchers. The research in it has evolved over time as new and ongoing techniques and models are introduced. We will go through its evolution and how the new techniques arrived and are working to resolve it. We will get an idea of how it was handled before and where it is now.
Video Captioning is the process of understanding and converting video to textual form. Captions act as quick snapshots of the ongoing action in a video, offering a clear and concise explanation of what's unfolding on screen. We describe the video in natural language that is understandable by humans using machine or computers. We do it using the application of Artificial Intelligence, specifically Computer Vision and Natural Language Processing. Both of these domains are the latest and emerging trends in our technology and day-to-day lives. In this article we will be looking into different techniques of video captioning and how it evolved over time. Computer Vision includes the process in which the video and visual information can be understood by the computer. All the work to make the computer make sense of what is going on in front of it is done in this domain. It includes the subjects, objects, surroundings and background and other things which are easy for humans to interpret but gets complex which in comes to machines. Natural Language Processing involves each and everything related to text description and textual processing and making the machine generate useful and senseful words related to query. Description of any video can be generated by the combination and utilization of these domains.

If we get towards the applications video captioning has a lot of applications and uses in our daily life and has immense potential to revolutions the tasks. Using video captioning we have bridged the gap between the video and text which was impossible few decades ago. Due to it we have the power to help humans and upgrade robots as well. They will be able to understand the surroundings and make sense of it as well. The ability to automatically generate coherent and contextually relevant captions for videos is crucial for enhancing human-computer interaction and accessibility to multimedia content.

The emerging trends look good and promising as more and more effort is being put in this field. The challenges that we face in video captioning are the ones what motivates us to look into it and explore it more. Researchers always try out new approaches to get the best description out of video, but video consists of a lot of information inside it. It is a collection of images spread over time and every frame has its own description which changes over time. The objects, actions, and interaction between them is important yet complex to comprehend for machine when it changes after time. The loss of information which is inside the long video is still under research. These sequences of actions add complexity, yet they are important to show the relationship between different events in the video.
The video captioning started with the predefined template and structure for sentence for caption. They were called template-based methods. After it comes the Deep learning-based methods, and it introduced the encoder decoder structure. The encoder, which is important part of the architecture took out the visual features from the input video. The decoder on the other hand was responsible for the result generation in textual form after processing the visual information that it gets from the encoder.
The encoder consisted of the CNN/RNN, and it took out the visual features. The decoder constitutes of RNNs. RNNs have the limitation of the vanishing gradient, which is a limitation when it comes to long range dependencies or sentence generation. Attention was introduced to address this limitation and LSTMs and GRUs were used in some models as well. It enables the models to look into and extract only the information which needs to be focused. It helped remove the vanishing gradient issue and hence improved the performance of the architecture.
After transformers came into the picture, both the encoder and decoder switched to using transformer technology, which got a lot of attention for delivering good results. People are still working on creating new and improved models to make them even better. Researchers are putting effort into finding the best solutions, aiming for optimized and reliable outcomes in various tasks like language processing. It's like an ongoing journey of discovery and improvement. As they keep working, we can expect more advancements in this technology.This process reflects the collective commitment to advancing the state-of-the-art in transformer-based technologies.
One of the old state of art models consists of the Sequence to Sequence model. It consisted of the LSTMs. LSTMs stands for Long Short-Term Memory. They are a type of RNNs. RNNs have the drawback of the vanishing gradient and loose information. LSTMs consist of gate mechanisms which update and forget information according to requirement. Particularly in the areas where long term information is required, then they are preferred over the simple RNN.
The input to the model is given in the form of the sequence of frames and output is the sequence of words in the form of sentence generated word by word. The problem was thought very near to the translation of the text. Just instead of the text converted into embedding it was the frames that were converted and to be used for the processing. The model utilized the stack of LSTMs for effective processing. The model is encoder and decoder based. The encoder consisted of the LSTMs converting the video frames and decoder consisted of the LSTMs that took those conversations and produce words.
The datasets that were used include the MSVD, MPII-MD and M-VAD. The RNN feature extractions were compared with pre-trained AlexNet and VGG CNNs. During training, the LSTM is constrained to a fixed 80 timesteps, ensuring consistent processing of input sequences. The model achieves a METEOR score of 27.9%, showcasing a significant improvement over the basic mean-pooled model. Mean Pool model consisted of the AlexNet and VGG CNN as well. No pretraining was done in this model as the concept was still unknown in video captioning. <EOS> (end of sentence) tag Is used so that the ending of a sentence gets clarified.
LSTMS were better but not the satisfactory solution to our problem of vanishing gradient. Attention was introduced and now it was giving out better results in other domains. The makers of this model claims that it is the first model which used attention in it. Attention mechanisms get rid of useless information and help the model to focus on the useful information only. They mimic the way humans selectively pay attention to specific details when processing information. If the attention is used in the model and integrated in the then it serves the purpose of the dominant module. In the dominant module the model has the attention as a dominant and separate module to work. On the other hand, in the assistant module attention works in the model to enhance the task in hand and assist it.
The model consists of the encoder, attention based recurrent decoder and attended memory decoder. The encoder takes out the relevant features of the video as usual. It includes the VGG, Google Net and Inception-V4.3D features were also extracted in it using the ResNeXt-101 for experimentation. The attention based recurrent decoder which is Soft Attention LSTM (SA-LSTM) based is used to generate the sentence from the features of the video generated using the encoder. Attended memory decoder just works I the enhancement of the generated captions. It tries to remove any redundancies.
The experiment was conducted on the MSVD and MSRVTT dataset. The model performed a lot better than S2VT model and took over it by 9 points in the BLEU-4 on MSR-VTT dataset. CIDEr score was improved by 11.9 points on the same one. About the MSVD dataset, CIDEr score for MARN is 92.2 and BLEU-4 is 48.6. Human evaluation was also conducted in it and the model won among 43.3% of the test samples.
Dense Video Captioning includes the generation of multiple descriptions from the same video. It depends on the events occurring in it and segments in video. Traditional video captioning includes the caption generation of full video and does not involve the events and segments inside it. Video2Sec is a multimodal video captioning model, and it takes input in the form of video as well as audio. Few-shot video captioning leverages the concept of few-shot learning, where models are trained on a small set of examples, often just a handful of video-caption pairs, to develop the capability to caption unseen videos.
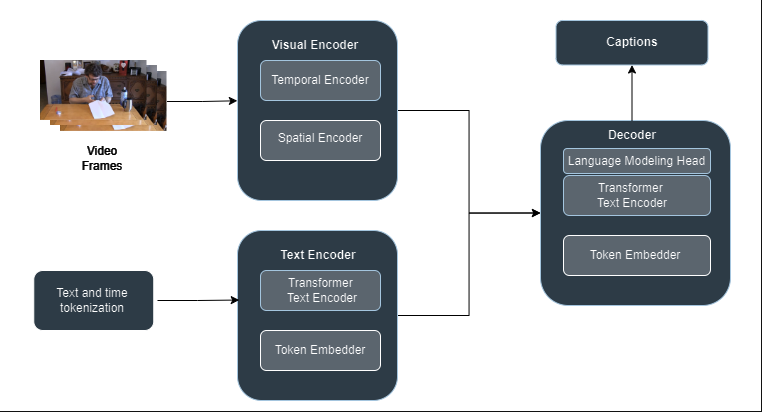
The speech in the video is transcribed and used as input along with the video. There are two encoders in it. The visual encoder and text encoder. After it comes the textual decoder which takes the embedding from both the encoders and then decode it inform of text word by word. CLIP model ViT-L/14 is used for visual encoding and T5-Base is used in the text encoder and decoder. It consists of the usual encoder decoder architecture, but it consists of transformers.
Dataset that was used includes the MSVD, MSR-VTT, YouCook2, ViTT and Activity Net. It was pretrained on HowTo100M and YT-Temporal-1B and then caption were generated on MSVD and MSR-VTT. The model performed better with an improved CIDEr score by 18.2 points on YouCook2 and 0.8 point on Activity Net dataset. It was compared and evaluated with other state of art, and it showed satisfying results as compared to them. Another thing that was experimented with was few shot captioning using this model. The results were satisfactory in it as well.
In zero shot learning, the model is given unseen scenarios in which it has to predict the output. It is not trained for it and the event are unknown to it in terms of the video captioning. It poses new challenges when the length of the video is long and there are no captions. ZeroTA (Zero-shot Temporal Aligner). This approach has helped us gain video caption when we have new kind of video. Although there is room for improvement in this area and work is still going on. New and better Zero shot Video Captioning models and techniques will be seen in the future.
The visual features are extracted using the CLIP model ViT-L/14. The pretrained GPT-2 model is used for text generation. Vision Loss and Language loss is integrated in it. ZeroTA servers the purpose of aligning the models and producing efficient result. Before this model such technique in video captioning is not seen. It has helped us generalize the model and make it explore new kind of content. Video2Sec
The datasets that were used includes the Activity NET and YouCook2 for the evaluation. It was compared to Vid2Seq, and it performed better. On the Activity NET dataset, the value for Video2Sec is 0.1 while it got 7.5 on CIDEr. On the other side if we look into the YouCook2 dataset it got 4.9 and Video2Sec got 0.5 on the same metrics.
In the conclusion I would like to state that from LSTMs where we got the loss of information due to vanishing gradient and now to zero shot dense video captioning where we have event related and generalized information, we have come a long way and getting toward a good solution to it. There are still limitations related to correct subject identification and interpretation and lot information gets lost when we have generalized things. Sentiments are still very important when we have whole event in the video which we also see missing. Hopefully in the future it will be resolved as we are going towards new and latest technology where we wish to see hardware limitations are less of a hurdle for researchers.