
Introduction:
Contrastive Language-Image Pretraining, or CLIP is a model which is developed by Open AI. It shows the improvement and advancement in AI, which now lets us know the relationship between image and text. Before CLIP there were ways to analyze it but they were not that good. This article aims to delve into the various facets of CLIP, exploring its architecture, applications, limitations, and the broader implications it holds for the future of machine learning.
Architecture and Working Principles:
Clip is based on the CONVIRT and it learns from the natural language supervision.The data set on which it was trained on was named as WIT(WebImageText).The data set consisted of the 400 million images and text pairs.It was collected using the 500,00 queries.By queries it is meant that keywords used to get the data.In total the image text pair per query becomes 20,000 images.It is the same approach that was used when GPT was trained by them.They used a big data set that was made by them and trained it on it .The transformers require large datasets and architectures.For efficiency and better results it is a very good approach if the required resources are available.
In the starting like any other model the approach was to give the model corpus of the data which includes the images and the text.It is concatenation of computer vision and natural language processing techniques.Image CNN was to be used and text based transformer is utilized after it.The drawback of such approach is that it was time taking and require high computational resources.If the resources are mange and latest hardware is there still time is the price which was to be paid and it was time consuming despite having clusters for training.Another drawback of such learning is that the model will be giving and predicting the words that are already in the vocabulary and will not be able to think or predict outside it.
The change in approach that was in this model was the use of contrastive learning instead of the old predictive approach.To implement it they did not train the model to give the exact word for the image shown.The main focus and thing to be tested was the word prediction in which the text as whole matches with with image.In other words or technical language which text embedding matches most with the respective image embedding.So the predictive approach was changes to contrastive approach and learning.In contrastive objective learning of the model is done differently.It is trained to differentiate the between the positive and negative pairs.The advantage of this approach was that it increased the efficiency of the model by four times as compared to predictive learning.
In this way when applied to task of image captioning the main objective was to see weather a certain image and text is present in the batch of the pairs that are given to it.During the training process the main aim is to minimize the similarity when the correct pairs are available.On the other hand,it should be minimized when we have incorrect pairs.
Multi modal embedding space is made during the learning in which image text pairs are matched. They are aligned together in such a way that the comparison between them is possible and facilitated.
As any other multi modal model the approach is to train it by giving it the data of one modality and Its architecture consists of the encoder for images as well as text. The image and text is encoded and they are kept side by side. Such design is made to learn meaningful representations of both images and text through a process known as contrastive learning. In the training process, CLIP is given bulk of images with their text descriptions. The model then learns to associate the correct image with text descriptions, and dissimilar content is pushed apart.
The vision encoder within CLIP processes images using convolution neural networks (CNNs), extracting hierarchical and abstract features. Simultaneously, the text encoder processes textual descriptions, converting them into high-dimensional vectors capturing semantic meaning.As the vector from the image and text are extracted. They are brought together such that they get compared and the diagonal ones (as shown in diagram) are ones that are most associated images and text. They are considered to be most relevant and others get ignored.
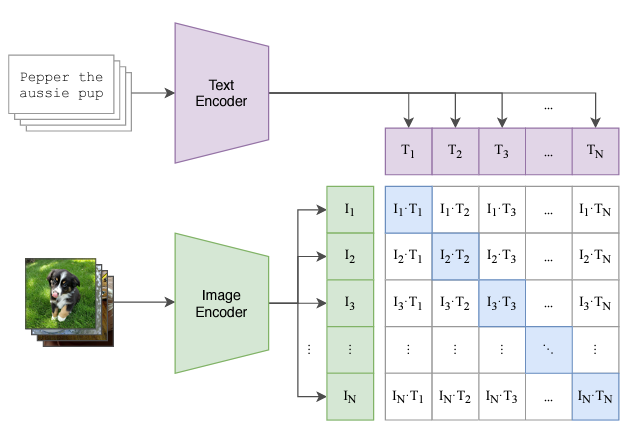 Referenced from https://openai.com/index/clip
Referenced from https://openai.com/index/clip
Zero-Shot Learning:
A standout feature of CLIP is its remarkable performance in zero-shot learning. This implies that the model can make accurate predictions on tasks or concepts it has never encountered during training, showcasing an unparalleled adaptability to new and unforeseen scenarios. This versatility positions CLIP as a powerful tool in dynamic and evolving environments.It can do that for both the text and image.The researchers tested it by giving prompts and let it predict the unseen object in the image.The results were satisfying and the model predicted the objects correctly.In other words the object detection was also done in it and zero shot prediction was performed on the objects.
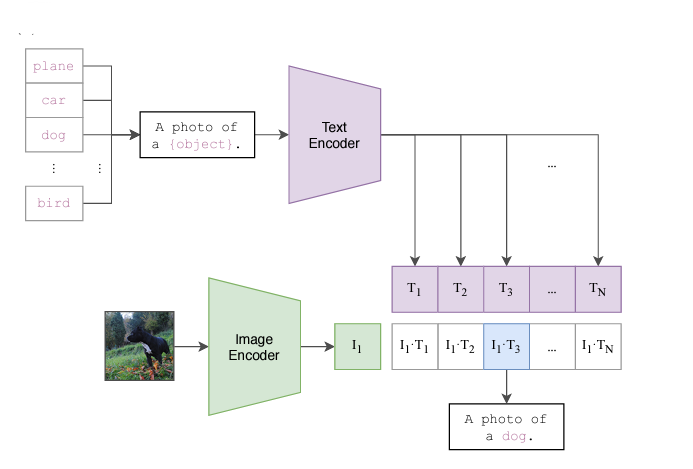 Referenced from https://openai.com/index/clip
Referenced from https://openai.com/index/clip
Applications of CLIP:
1. Image Classification
CLIP is useful when it comes to image classification .Its zero shot capabilities help make it more trust worthy and meaning full.For the Image classification the architecture that will be used consist of the one for image processing(ViT or ResNet).The encoder for the text consist of the model that is similar to GPT.
2. Object Detection
The model can also do object detection, identifying and locating objects within images. The multi modal pre training enables CLIP to comprehend complex scenes and recognize diverse objects.Prompt type object detection can be done if a prompt is set and when ever an object is detected it tell about the object and it is detected.Although it does not make the bounding boxes around the objects but it is able to detect it.Localization of the object is not possible though.For that it needs to be attached with a object localization algorithm.
3. Visual Question Answering (VQA)
CLIP's application extends to Visual Question Answering tasks, where it answers questions about the content of images. The model's ability to comprehend and generate responses based on representations makes it well-suited for natural language understanding tasks.Visual Question answering is a new domain and it tells about what it is watching.CLIP is very helpful in it as we can question anything using the model.Although it was not basically made of the video questioning answering but the architecture flexibility allows it to handle VQA.
4. Cross-Modal Retrieval
In cross-modal retrieval, CLIP demonstrates its capability to seamlessly navigate between different modalities. Users can search for images based on textual descriptions or find relevant textual descriptions for given images. This functionality enhances search and retrieval systems, providing users with a more intuitive and effective way to explore multi modal datasets.As there are other modalities like sound inspiration can be taken and such approach can also be utilize in it.
5. Natural Language Understanding
Given its training on language and images, CLIP proves efficient at natural language understanding tasks. It can generate meaningful representations of textual descriptions, expanding its applicability to a range of linguistic tasks such as sentiment analysis, summarization, and language translation.It can be utilized anywhere where the is visual description given and the textual description is needed or vise versa.That is very power full trait that comes in the positive aspects of CLIP.
Limitations and Challenges:
Looking at these points it is safe to say that every things has its pros and cons and we have to look at both of the factors.We have to be careful about where it can be applied and ideal and where we have to switch our options.Despite its limitations it one of innovative and different model that is being used and popular right now.It has given a kick start to the new models in contrastive learning which will have different modality interaction in it.
Implementation of CLIP :
One of the implementation of the clip consist of the use in video captioning.Its multi modal capabilities of tackling with image and text help it achieve this task.The video is taken in and converted into multiple frames or images.After that any of the CLIP pretrained weights can be used to extract features.As the feature embedding are extracted by clip then they are sent towards the ChatGPT for the conversion into meaning full explanation.The loss is calculated for the vision and the text and after that is fed back to the model so that it can generate better captions.The sentence fully generated is considered as token.After each and every token the caption gets better and matches the video.It is very useful as CLIP has zero shot capabilities and Chat GPT model gets the best natural language description in the form of text.It is vary effective use of the powerful models.
Conclusion:
In conclusion, CLIP is a transformer model which has introduced the contrastive learning with respect to image and text in the field of artificial intelligence, bridging the gap between images and text with unprecedented efficiency.Using of comparative analysis and reaching out to results id innovative and different than the traditional predictive approaches. Its ability to seamlessly integrate multi modal information (images and text) opens new doors in various applications, from image understanding to natural language processing. While challenges and limitations exist, the overall impact and potential of CLIP is important. As research progresses, refinements in architecture and training methodologies may further enhance the capabilities of models inspired by CLIP.
Powered by Froala Editor