
This research endeavors to explore a model tailored for Urdu Handwritten Character Recognition through image data employing a spectrum of Artificial Intelligence technologies i.e; ML primarily known and Machine Learning. The primary aim is to conduct a comprehensive comparative analysis on Urdu Handwritten Characters utilizing an extensive dataset.
Methodology and Statistical Analysis: The research focuses on analyzing the effectiveness of Machine Learning models for analyzing the handwritten characters in Urdu Language. For this purpose, investigated the wide range of models including Logistic Regression, SVM (Support Vector Machine), MLP(Multi-Layer Perceptron), RF(Random Forest) and DT(Decision Tree).
Key Findings: Despite the extensive research in the domain of English Language, the literature review underscores a dearth of studies focusing on Urdu Handwritten character recognition via image data. Moreover, analysis from this research underscores the superior efficacy of Machine Learning models over RF, SVM, and MLP in producing robust results with optimal accuracy. This proposed study beholds significant importance in learning Urdu handwritten characters by representing a smooth and automated learning process through the advancement of technology.
Keywords: Urdu Handwritten Digits Recognition; Machine Learning; Urdu Characters.
One of the most difficult problems in pattern recognition research is automatically recognizing handwritten text from images and various other materials. The task is to recognize the different forms or patterns that is present in handwritten text, where each word embodies a unique form that reflects the various writing styles of individuals. It extends its linguistic influence to countries such as Afghanistan, India, and Bangladesh, with its literature spanning multiple languages.
Despite Urdu's prominence, research into Urdu handwritten text recognition remains relatively scant, with the first significant script emerging in 2004, focusing on Optical Character Recognition [1–7]. Referred to as Intelligent Character Recognition (ICR), the pursuit of Urdu handwritten text recognition using images has encountered challenges in delivering robust systems capable of producing dependable results. Contrastingly, for printed text, Optical Character Recognition (OCR) systems exist, albeit limited to printed text and not handwritten variants.
Various algorithms of different domains including ML have been employed in the quest for handwritten Urdu text recognition, utilizing numerical labels rather than Urdu-specific ones, ranging from 0 to 39. Notably, Support Vector Machine (SVM) represents the machine learning domain, while Multi-Layer Perceptron (MLP), Random Forest, Decision Tree, and LeNet5 constitute the deep learning approaches, exhibiting promising outcomes. Through meticulous analysis and comparison, these algorithms' efficacy has been evaluated to ascertain their accuracy and reliability, with deep learning methodologies emerging as more precise, surpassing conventional techniques [8].
Additionally, research-based recommendations support the application of deep learning algorithms for text extraction and recognition, highlighting the intricate structure of Urdu language numbers. This highlights the challenges associated with digit identification resulting from a variety of unique writing styles. Urdu script, written from right to left, compounds the complexity, further compounded by its cursive nature [9].
The proposed system holds potential benefits, particularly for individuals unfamiliar with Urdu but keen on learning to write it. By leveraging the system, users can compare their handwritten words against the system's database, facilitating self-assessment and correction, ensuring accurate reproduction of Urdu alphabets.
The background study illuminates the scant exploration of Urdu language in the realm of image-centric research, particularly when juxtaposed with other linguistic domains. Despite Urdu being spoken by millions, an orchestrated and streamlined system is required for recognizing Urdu handwritten characters from images remains conspicuously absent. Notably, Cakmakov et al [10] devised a model for Roman digit recognition achieving an impressive 97% accuracy, leveraging the support vector machine.
This model extracts four attributes—ring-zone, contour profiles, histogram projections, and features of Kirsch—from the provided images. Employing Principal Component Analysis (PCA), the model reduces the feature space from 256 dimensions to 128 directional features. The simulations conducted hold promise for diverse applications, including pattern classification, recognition, and alphabet identification across languages like Urdu and Sindhi. Notably, for handwritten digit recognition, this model adopts the backpropagation technique, relying on minimal data preprocessing. During testing, the model exhibited a mere 1% error rate and a 9% rejection rate.
Given the inherent challenges posed by variations in handwriting, handwritten Urdu character recognition via images emerges as a formidable task. Multiple studies underscore the pervasive utilization of Artificial Neural Networks (ANNs) for character recognition. ANNs comprise interconnected nodes through which signals and information flow, enabling the model to train itself based on provided inputs to generate labeled outputs. However, a significant hurdle lies in devising a universal system applicable across languages, given the distinct styles and character sets inherent to each language.
An approach based on open mining proposed by Mangat Veenu et al. [11], in the study oversees several methods for sentiment analysis, such as naïve Bayes, SVM, and random forest. It examines datasets from Amazon, Flipkart, and IMBD to train models to understand sentiment and extract word context.
The literature survey laid the strong foundation for analyzing and discussing the core methods of Urdu Handwritten Digit Recognition so, as to have a deep look into the methods that assist us in deep-diving the realm of Machine Learning models for day-to-day ask make it efficient and effective for the everyone.
Pre-Processing:
The evaluation of the model's performance is quite a unique task, the technique of gathering datasets plays an intriguing role in analyzing the results. An accurate collection of handwritten characters from a range of people, each encouraged to write in their way, added a variety of examples to the model's training set. The collection, which includes about three thousand photos, has four words: Alif, Baa, Jeem, and Daal. The photographs come from a diverse range of contributors belonging to different domains.
All the images are separated and transfigured in the form of the array so they can be input into the models. The dataset has been gathered using high-resolution cameras and the OCR techniques has been applied to transform them into the dataset.
There are two separate subsets of the dataset, one for testing and the other for training. It has three thousand 50x50 size images in total. Specifically, 2500 image samples are used to train the model, and the remaining 500 examples are reserved for assessing the model's effectiveness.
MLP:
The Multi-Layer Perceptron (MLP) is an architectural masterpiece in the domain of artificial neural networks. It is a complex feedforward model that has been methodically constructed to perform learning tasks and reduce mistakes through the iterative process of backpropagation. The main point of concern that distinguishes MLP from linear perceptron is its utilization of multiple layers and non-linear activation functions. Neurons within the network are interconnected, with the activation function specifying their behavior. Notably, the MLP model adeptly handles linearly inseparable data, facilitating effective classification. Moreover, the MLP model governs and facilitates communication between input and output layers. The results yielded by the MLP model are indicative of its efficacy in various learning tasks. The accuracy and results achieved by MLP are shown in figure below as:
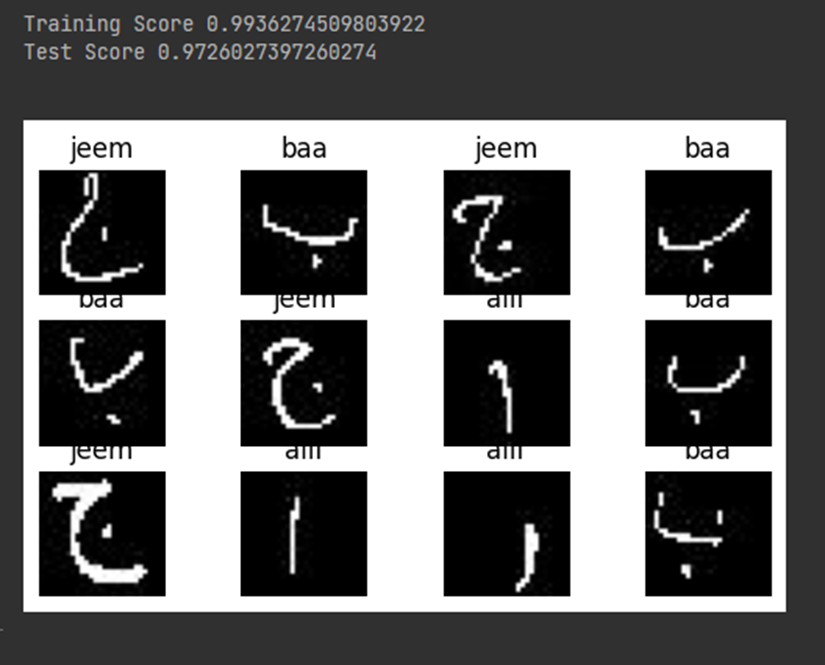
The training accuracy is 99%, whereas the test accuracy is 97.2%.
Support Vector Machine (SVM):
Support vector machines (SVMs) serve as powerful tools for analyzing, classifying, and conducting linear regression on provided datasets within the realm of supervised learning [12]. By constructing a model, SVMs partition data into distinct categories and subsequently allocate newly encountered data points to these categories, rendering SVMs as non-probabilistic binary linear classifiers.
Within the SVM framework, data categories are represented by mapping them onto spaces, facilitating clear visualization and comprehension of the dataset. Similarly, newly encountered data points undergo the same mapping procedure, accounting for the gaps between different categories. Notably, SVMs possess the capability to tackle non-linear classification tasks through a technique known as the kernel trick, wherein inputs are mapped into high-dimensional feature spaces. The efficacy of SVMs is visually demonstrated in the figure below.:

The training accuracy is almost 99.3% and test accuracy is 97%.
The few techniques has been applied and their results have been shown to a brief over-view of the classification techniques.
| Machine Learning Techniques | Accuracy Achieved |
| Logistic Regression | Training Acc: 0.9921568627450981 Test Acc: 0.9432485322896281 |
| Support Vector Machine | Training Acc: 0.9931372549019608 Test Acc: 0.9726027397260274 |
| Decision Tree | Training Acc: 1.0 Test Acc: 0.7808219178082192 |
| Random Forest | Training Acc: 1.0 Test Acc: 0.9080234833659491 |
| Multi-layer Perceptron | Training Accu: 0.9936274509803922 Test Acc: 0.9726027397260274 |
| LeNet5 | Training Acc: 0.9746 Test Acc: 0.974559686888454 |
The current model demonstrates proficiency in recognizing given input images. However, the diverse array of writing styles poses limitations on handwritten character recognition within this research. To address this challenge, future endeavors will focus on expanding existing techniques to encompass the intricacies of Urdu language phonetics in a more sophisticated manner.