
LLMs are AI algorithms that use neural networks for natural language processing. They are being used as chatbots, text generators and summarizers, language translators, and code generators. They find several applications in fields like healthcare, education, and e-commerce. Deployment means making a product accessible for use. So, LLM deployment refers to making the LLM available for users.
Hugging Face is a hub of AI and ML models and focuses mainly on NLP. It provides easy and free deployment options. It provides a free storage quota, and after that,t it provides paid resources. It has inference providers, which means that API calls are directed to third-party inference providers. There are two approaches to deploying LLMs on Hugging Face:
We will go through a tutorial for both approaches and create a comparison of each in this blog.
In this approach, the model is hosted by Hugging Face and is ready for public use. For this, we need to upload our trained LLM and supporting files to Hugging Face. The model can then be used via an inference API or by directly loading it from the Transformers library. There are two ways to call inference APIs, via a custom key or through routing. In case of a custom key, the inference calls are sent to third-party inference providers directly. While in routing, the inference calls are routed by Hugging Face, and the bill is added to the Hugging Face account.
Hugging Face provides two templates, base template and diffusion LoRA template. The base template serves as the core model architecture without any fine-tuning and modifications. The diffusion LoRA template refers to a LoRA adapter applied to a diffusion model. It is mainly used for diffusion models. So, we will be using the base template for deploying LLMs.
Let’s go through the steps to deploy LLM as a model:
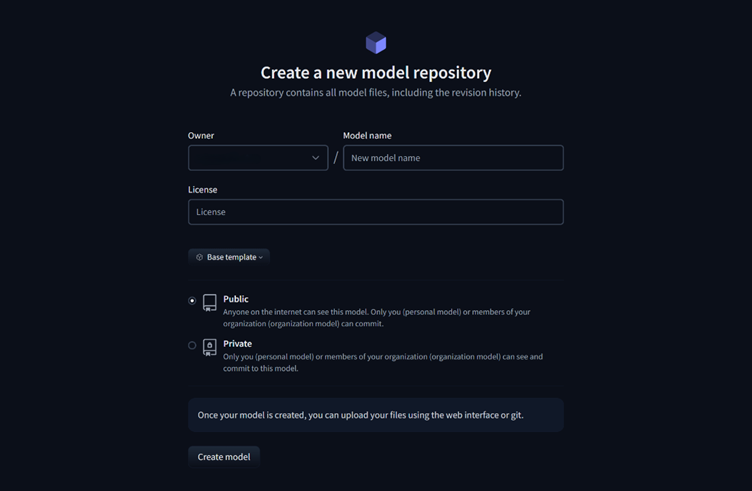
4 . Add a name for your model and select public or private. Public means that the model can be seen by everyone, but only you and your organization members can make changes to it. Private means that only you and your organization can see and make changes to the model.
5. You can also add a license for your model to restrict commercial use and modifications. Some common licenses include MIT, Apache 2.0, CC BY 4.0, Non-Commercial and Proprietary. MIT and Apache 2.0 are open and allow commercial use and modifications. CC BY 4.0 is open but allows commercial use with attribution. Non-Commercial is restrictive but does not allow for commercial use, but allows for modifications. Proprietary is closed and does not allow for commercial use or modifications usually.
6. Click on Create Model, and your model is created.
7. Upload your pre-trained model and other supporting files like model weights, configuration, tokenizer, and inference scripts.
8. Your model is hosted by Hugging Face and ready to use for users.
In this approach, our LLM is deployed as a web-based app. For this we need two files, app.py and requirements.txt. The app.py contains the application designed for interacting with LLM, and requirement.txt contains the libraries and packages that need to be installed for the model to work. The app is built and run by Hugging Face automatically.
Steps:
Let’s go through the steps to deploy LLM as a model:
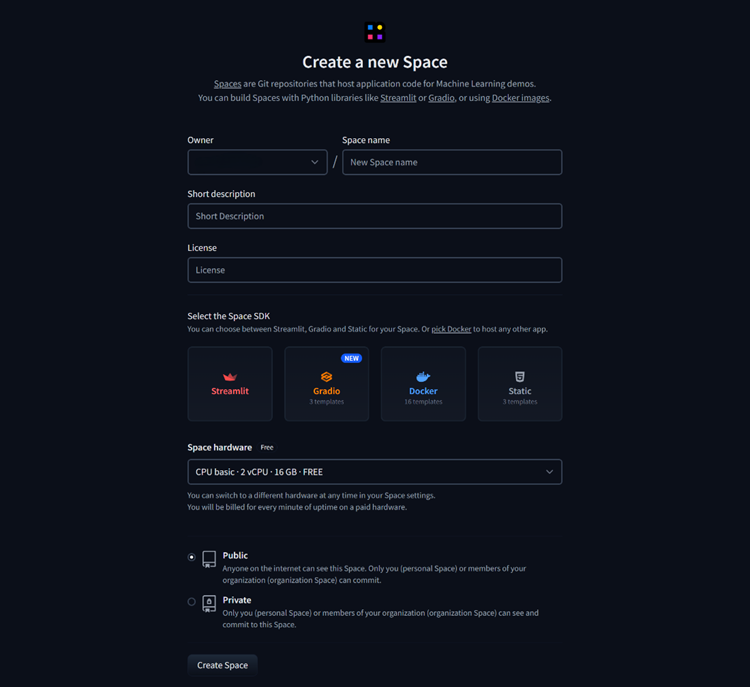
You can find an example tutorial of deploying a chatbot using the Mistral API here: Link

Deployment as a Model | Deployment as a Space |
The users can access the model via API calls without any complexity. | The app is less efficient for API calls.
|
It provides limited customization, i.e., no user interface. | It provides several templates to build interactive user interfaces. |
Cannot be used by non-technical users without UI. | Non-technical users can easily interact with the app through the UI. |
Users can optimize the LLM and fine-tune it for their specific use. | It is difficult to download and fine-tune models from spaces. |
It provides less control over hardware than spaces. | Provides more control over hardware. |
It is limited to technical users. | It can be used by technical as well as non-technical users. |
Users can easily load the model from the Transformers library. | The app may be slow if the model is large and resources are insufficient. |
Hugging Face makes deployment easy for direct API usage and interactive apps. Both approaches have their own pros and cons. Deployment as a model is fast and efficient but provides limited customization. Deployment as a space provides interactive user interfaces and built-in templates but are inefficient for API usage. Choosing the right approach depends on the use case and resources available.
Powered by Froala Editor