
Text generation models, like GPT, BERT, or T5, have revolutionized how we interact with machines. These models generate human-like text, but how do we evaluate the quality of the text they produce? That’s where evaluation metrics come in. In this post, we’ll explore the most common metrics used to evaluate text generation models. We'll break them down step by step, with formulas and examples.
BLEU is one of the most widely used metrics for evaluating machine-generated text. Originally developed for machine translation, BLEU measures the precision of n-grams in the generated text when compared to a reference text.
The BLEU score is calculated as follows:
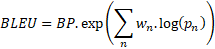
![]()
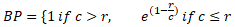
![]()
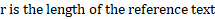
![]()
The F1-score is the harmonic mean of precision and recall, providing a balanced evaluation of both metrics. It is widely used in classification tasks, including text generation.
Formula:
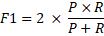
P is precision.
R is recall.
• The F1-score combines both precision and recall into a single metric.
• It’s especially useful when you want to balance the two metrics
• A higher F1-score indicates a better balance between precision and recall.
SPICE measures the semantic content of a generated text by comparing the propositions (subject, predicate, object) extracted from the text and reference. It’s mostly used for image captioning tasks but can also be applied to text generation.
Formula:
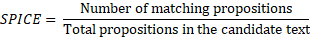
ROUGE-L evaluates the longest common subsequence (LCS) between the candidate and reference text. LCS considers the longest sequence of words that appear in both texts in the same order, making it useful for tasks requiring semantic similarity.
Formula:
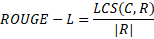
LCS(C, R) is the length of the longest common subsequence between the candidate (C) and reference (R).
|R| is the length of the reference text.
• ROUGE-L captures word order and semantic alignment by focusing on subsequences.
• Higher scores indicate better alignment with the reference.
• It is especially useful when word order and longer semantic structure matter.
Precision at k (P@k) is a metric that calculates the precision of the top k results. It is often used in ranking tasks like document retrieval or in scenarios where multiple candidate responses are generated.
Formula:
![]()
![]()
![]()
![]()
Syntax-based measures evaluate the syntactic correctness of the generated text, such as its adherence to grammatical rules and sentence structures. Parse trees are often used to assess these metrics.
Formula:
![]()
![]()
![]()
![]()
Chrf is a metric similar to F1 but operates at the character level rather than word level. It is useful for evaluating text generation where minor spelling differences matter, such as character-level tasks.
Formula:
![]()
![]()
![]()
![]()
LLR is used to assess the statistical significance of the match between generated and reference text. It compares the probability distributions of the candidate and reference texts to determine if the generated text is similar in terms of word choice.
Formula:
![]()
![]() is the observed frequency of the i-th word in the candidate text.
is the observed frequency of the i-th word in the candidate text.
![]() is the expected frequency of the i-th word based on the reference.
is the expected frequency of the i-th word based on the reference.
SARI is a metric designed for text simplification tasks. It measures how well the system output maintains the meaning of the reference text while simplifying it, comparing generated sentences to reference simplifications.
Formula:
![]()
Syntax-based measures evaluate the syntactic correctness of the generated text, such as its adherence to grammatical rules and sentence structures. Parse trees are often used to assess these metrics.
Formula:
![]()
Perplexity is a measure of how well a language model predicts a sequence. It quantifies the uncertainty of the model’s predictions: lower perplexity values indicate better performance
Formula:
![]()
CIDEr is a metric primarily used for evaluating image captioning but is also applicable to text generation. It measures the consensus between the candidate and reference texts, using TF-IDF weighting to account for word importance.
Formula:
![]()
Evaluating text generation models is not a one-size-fits-all task. Depending on the task (e.g., translation, summarization, image captioning), the appropriate metric may vary. Each metric has its strengths and weaknesses, and the key to effective evaluation lies in using multiple metrics to get a comprehensive understanding of a model’s performance.
Powered by Froala Editor